

AI image synthesis has made impressive progress since Generative Adversarial Networks (GANs) were introduced in 2014. GANs were originally only capable of generating small, blurry, black-and-white pictures, but now we can generate high-resolution, realistic and colorful pictures that you can hardly distinguish from real photographs.
Here we have summarized for you 5 recently introduced GAN architectures that are used for image synthesis.
If these accessible AI research analyses & summaries are useful for you, you can subscribe to receive our regular industry updates below.
For those of you who are less familiar with GANs, let’s recall what a GAN is and how we can use these neural network approaches for image generation.
What is GAN?
- A generative adversarial network (GAN) is a type of machine learning technique made up of two neural networks contesting with each other in a zero-sum game framework.
- The two neural networks that make up a GAN are:
- a generator with a goal to generate new instances of an object that will be indistinguishable from the real ones, and
- a discriminator with a goal to identify the fakes.
- GANs can be used to create all types of content including images, video, text, audio.
If you’d like to skip around, here are the papers we featured:
- StarGAN: Unified Generative Adversarial Networks for Multi-Domain Image-to-Image Translation
- AttnGAN: Fine-Grained Text to Image Generation with Attentional Generative Adversarial Networks
- High-Resolution Image Synthesis and Semantic Manipulation with Conditional GANs
- Large Scale GAN Training for High Fidelity Natural Image Synthesis
- A Style-Based Generator Architecture for Generative Adversarial Networks
New Generative Adversarial Network GAN Architectures for Image Generation
1. StarGAN: Unified Generative Adversarial Networks for Multi-Domain Image-to-Image Translation, by Yunjey Choi, Minje Choi, Munyoung Kim, Jung-Woo Ha, Sunghun Kim, Jaegul Choo
Original Abstract
Recent studies have shown remarkable success in image-to-image translation for two domains. However, existing approaches have limited scalability and robustness in handling more than two domains, since different models should be built independently for every pair of image domains. To address this limitation, we propose StarGAN, a novel and scalable approach that can perform image-to-image translations for multiple domains using only a single model. Such a unified model architecture of StarGAN allows simultaneous training of multiple datasets with different domains within a single network. This leads to StarGAN’s superior quality of translated images compared to existing models as well as the novel capability of flexibly translating an input image to any desired target domain. We empirically demonstrate the effectiveness of our approach on a facial attribute transfer and a facial expression synthesis tasks.
Our Summary
The paper introduces a novel architecture for image-to-image translation, called StarGAN. Using a single generator and a discriminator, the model can (1) translate images across multiple domains and (2) learn from multiple datasets with different types of domain information. The experiments show that the suggested approach significantly outperforms baseline models in facial attribute transfer and facial expression synthesis. The performance gap is especially evident for multi-attribute transfer tasks.

What’s the core idea of this paper?
- StarGAN is a scalable image-to-image translation model that can learn from multiple domains using a single network:
- Instead of learning a fixed translation (e.g., young-to-old), the generator takes in as inputs both image and domain information to generate the image in the corresponding domain.
- Domain information is provided as a label (e.g., binary or one-hot vector).
- StarGAN can also learn from multiple datasets containing different types of labels:
- For example, the authors show how the model is trained with both the CelebA dataset with such attributes as hair color, gender, and age and the RaFD dataset with the labels corresponding to facial expressions.
- With a mask vector added to the domain label, the generator learns to ignore the unknown labels, and focus on the explicitly given label.
What’s the key achievement?
- Qualitative and quantitative evaluations show that StarGAN outperforms baseline models in facial attribute transfer and facial expression synthesis:
- The advantage is especially clear in more complicated, multi-attribute transfer tasks reflecting StarGAN’s ability to handle image translation with multiple attribute changes.
- StarGAN also generates more visually appealing images due to its implicit data augmentation effect from multi-task learning.
What does the AI community think?
- This research paper was accepted for oral presentation at CVPR 2018, the key conference on computer vision.
What are future research areas?
- Exploring the ways to further improve the visual quality of generated images.
What are possible business applications?
- Image-to-image translation can be used to reduce the costs of media creation for advertising and e-commerce purposes.
Where can you get implementation code?
- Official PyTorch implementation of StarGAN is available on GitHub.
2. AttnGAN: Fine-Grained Text to Image Generation with Attentional Generative Adversarial Networks, by Tao Xu, Pengchuan Zhang, Qiuyuan Huang, Han Zhang, Zhe Gan, Xiaolei Huang, Xiaodong He
Original Abstract
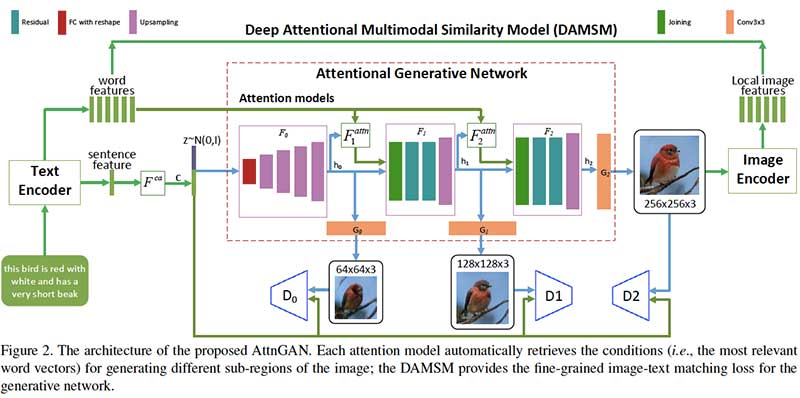
In this paper, we propose an Attentional Generative Adversarial Network (AttnGAN) that allows attention-driven, multi-stage refinement for fine-grained text-to-image generation. With a novel attentional generative network, the AttnGAN can synthesize fine-grained details at different subregions of the image by paying attentions to the relevant words in the natural language description. In addition, a deep attentional multimodal similarity model is proposed to compute a fine-grained image-text matching loss for training the generator. The proposed AttnGAN significantly outperforms the previous state of the art, boosting the best reported inception score by 14.14% on the CUB dataset and 170.25% on the more challenging COCO dataset. A detailed analysis is also performed by visualizing the attention layers of the AttnGAN. It for the first time shows that the layered attentional GAN is able to automatically select the condition at the word level for generating different parts of the image.
Our Summary
The researchers introduce an Attentional Generative Adversarial Network (AttnGAN) for synthesizing images from text descriptions. The model consists of two components: (1) attentional generative network to draw different subregions of the image by focusing on words relevant to the corresponding subregion and (2) a Deep Attentional Multimodal Similarity Model (DAMSM) to compute the similarity between the generated image and text description. The experiments show that AttnGAN performs significantly better than the previous state-of-the-art approaches and boosts the inception score by 170% on the challenging COCO dataset.
What’s the core idea of this paper?
- Fine-grained high-quality image generation can be achieved via multi-level (e.g., word level and sentence level) conditioning. Thus, the researchers suggest an architecture where the generative network draws different subregions of the image conditioning on the words that are most relevant to those subregions.
- An introduced model, Attentional Generative Adversarial Network has two novel components:
- Attentional generative network, where:
- a global sentence vector is utilized to generate a low-resolution image in the first stage;
- a regional image vector is combined with the corresponding word-context vector to generate new image features in the surrounding subregions.
- Deep Attentional Multimodal Similarity Model (DAMSM) that computes the similarity between the generated image and text description, providing an additional fine-grained image-text matching loss for training the generator.
- Attentional generative network, where:
What’s the key achievement?
- Establishing a new state of the art in the text-to-image generation by achieving an inception score of:
- 4.36 on the CUB dataset (+ 14.14%);
- 25.89 on the more challenging COCO dataset (+ 170.25%).
- Demonstrating that the layered conditional GAN is able to automatically focus on the relevant words to form the right condition for image generation.
What does the AI community think?
- The paper was presented at CVPR 2018, the key conference on computer vision.
What are future research areas?
- Exploring the ways to make the model better at capturing global coherent structures.
- Increasing the photo-realism of the generated images.
What are possible business applications?
- Automatic generation of images according to text descriptions can boost the efficiency of computer-aided design and art generation.
Where can you get implementation code?
- PyTorch implementation of AttnGAN is available on GitHub.
3. High-Resolution Image Synthesis and Semantic Manipulation with Conditional GANs, by Ting-Chun Wang, Ming-Yu Liu, Jun-Yan Zhu, Andrew Tao, Jan Kautz, Bryan Catanzaro
Original Abstract
We present a new method for synthesizing high-resolution photo-realistic images from semantic label maps using conditional generative adversarial networks (conditional GANs). Conditional GANs have enabled a variety of applications, but the results are often limited to low-resolution and still far from realistic. In this work, we generate 2048×1024 visually appealing results with a novel adversarial loss, as well as new multi-scale generator and discriminator architectures. Furthermore, we extend our framework to interactive visual manipulation with two additional features. First, we incorporate object instance segmentation information, which enables object manipulations such as removing/adding objects and changing the object category. Second, we propose a method to generate diverse results given the same input, allowing users to edit the object appearance interactively. Human opinion studies demonstrate that our method significantly outperforms existing methods, advancing both the quality and the resolution of deep image synthesis and editing.
Our Summary
In this paper, NVIDIA introduces a generative adversarial network for synthesizing high-resolution (2048×1024) photo-realistic images from semantic label maps. They base their approach on the new robust adversarial learning objective, as well as new multi-scale generator and discriminator architectures. This new approach substantially outperforms previous methods in the accuracy of semantic segmentation and photo-realism. Furthermore, the researchers extend their framework to support interactive semantic manipulations such as changing the object category, adding/removing objects or changing the color and texture of objects.

What’s the core idea of this paper?
- The new framework for synthesizing high-resolution images, called pix2pixHD is based on pix2pix method with several improvements:
- coarse-to-fine generator: training a global generator to synthesize images at a resolution of 1024×512 and then training local enhancers to increase the resolution;
- multi-scale discriminators: using 3 discriminators that operate at different image scales;
- improved adversarial loss:incorporating a feature matching loss based on the discriminator.
- The framework also allows interactive object editing thanks to adding additional low-dimensional feature channels as the input to the generator network.
What’s the key achievement?
- The introduced pix2pixHD approach outperforms state-of-the-art methods by a significant margin based on:
- a pixel-wise accuracy of semantic segmentation with a score of 83.78 (+5.44 from pix2pix baseline and only 0.51 points below the accuracy on original images);
- pairwise comparison by human evaluators conducted on different datasets and with different time settings (unlimited time and limited time).
What does the AI community think?
- This research paper was accepted for oral presentation at CVPR 2018, the key conference on computer vision.
- “These GAN results are very impressive. If you’re making a living from touching up images in Photoshop right now it may be time to look for something else“, – Denny Britz, deep learning researcher.
What are possible business applications?
- The suggested approach provides new tools for higher-level image editing such as adding/removing objects or changing the appearance of existing objects.
Where can you get implementation code?
- NVIDIA provides PyTorch implementation of this research paper.
4. Large Scale GAN Training for High Fidelity Natural Image Synthesis, by Andrew Brock, Jeff Donahue, and Karen Simonyan
Original Abstract
Despite recent progress in generative image modeling, successfully generating high-resolution, diverse samples from complex datasets such as ImageNet remains an elusive goal. To this end, we train Generative Adversarial Networks at the largest scale yet attempted, and study the instabilities specific to such scale. We find that applying orthogonal regularization to the generator renders it amenable to a simple “truncation trick”, allowing fine control over the trade-off between sample fidelity and variety by truncating the latent space. Our modifications lead to models which set the new state of the art in class-conditional image synthesis. When trained on ImageNet at 128×128 resolution, our models (BigGANs) achieve an Inception Score (IS) of 166.3 and Frechet Inception Distance (FID) of 9.6, improving over the previous best IS of 52.52 and FID of 18.65.
Our Summary
DeepMind team finds that current techniques are sufficient for synthesizing high-resolution, diverse images from available datasets such as ImageNet and JFT-300M. In particular, they show that Generative Adversarial Networks (GANs) can generate images that look very realistic if they are trained at the very large scale, i.e. using two to four times as many parameters and eight times the batch size compared to prior art. These large-scale GANs, or BigGANs, are the new state-of-the-art in class-conditional image synthesis.

What’s the core idea of this paper?
- GANs perform much better with the increased batch size and number of parameters.
- Applying orthogonal regularization to the generator makes the model responsive to a specific technique (“truncation trick”), which provides control over the trade-off between sample fidelity and variety.
What’s the key achievement?
- Demonstrating that GANs can benefit significantly from scaling.
- Building models that allow explicit, fine-grained control of the trade-off between sample variety and fidelity.
- Discovering instabilities of large-scale GANs and characterizing them empirically.
- BigGANs trained on ImageNet at 128×128 resolutions achieve:
- an Inception Score (IS) of 166.3 with the previous best IS of 52.52;
- Frechet Inception Distance (FID) of 9.6 with the previous best FID of 18.65.
What does the AI community think?
- The paper is under review for next ICLR 2019.
- After BigGAN generators become available on TF Hub, AI researchers from all over the world are playing with BigGANs to generate dogs, watches, bikini images, Mona Lisa, seashores and many more.
What are future research areas?
- Moving to larger datasets to mitigate GAN stability issues.
- Exploring the possibilities to reduce the number of weird samples generated by GANs.
What are possible business applications?
- Replacing expensive manual media creation for advertising and e-commerce purposes.
Where can you get implementation code?
- A BigGAN demo implemented in TensorFlow is available to use on Google’s Colab tool.
- Aaron Leong has a Github repository for BigGAN implemented in PyTorch.
5. A Style-Based Generator Architecture for Generative Adversarial Networks, by Tero Karras, Samuli Laine, Timo Aila
Original Abstract
We propose an alternative generator architecture for generative adversarial networks, borrowing from style transfer literature. The new architecture leads to an automatically learned, unsupervised separation of high-level attributes (e.g., pose and identity when trained on human faces) and stochastic variation in the generated images (e.g., freckles, hair), and it enables intuitive, scale-specific control of the synthesis. The new generator improves the state-of-the-art in terms of traditional distribution quality metrics, leads to demonstrably better interpolation properties, and also better disentangles the latent factors of variation. To quantify interpolation quality and disentanglement, we propose two new, automated methods that are applicable to any generator architecture. Finally, we introduce a new, highly varied and high-quality dataset of human faces.
Our Summary
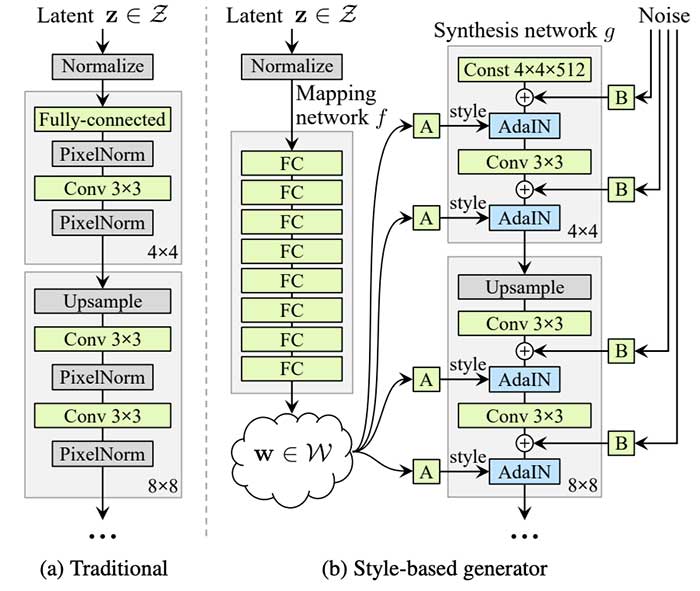
NVIDIA team introduces a novel generator architecture StyleGAN, borrowing from style transfer literature. In this research, they addressed the problem of very limited control over the images generated with traditional GAN architectures. A generator in StyleGAN automatically learns to separate different aspects of the image without any human supervision, making it possible to combine these aspects in many different ways. For example, we can take gender, age, hair length, glasses, and pose from one person and all the other aspects from another person. The resulting images outperform the previous state of the art in terms of quality and realism.
What’s the core idea of this paper?
- StyleGAN is based on a Progressive GAN setup, where each layer of the network is assumed to control different visual features of the image, and the lower the layer, the coarser the features it affects:
- layers corresponding to coarse spatial resolutions (4×4 – 8×8) enable control over pose, general hairstyle, face shape etc.;
- middle layers (16×16 – 32×32) affect smaller scale facial features such as hairstyle, eyes open/closed etc.;
- layers corresponding to fine resolutions (64×64 – 1024×1024) bring mainly the color scheme and microstructure.
- Motivated by style-transfer literature, the NVIDIA team introduces a generator architecture that enables novel ways to control the image synthesis process:
- omitting the input layer and starting from a learned constant instead;
- adjusting the image “style” at each convolution layer, allowing direct control over the strength of image features at different scales;
- adding Gaussian noise after each convolution to .generate stochastic detail.
What’s the key achievement?
- Getting a Frèchet inception distance (FID) score of 5.06 on CelebA-HQ dataset and 4,40 on Flickr-Faces-HQ dataset.
- Presenting a new dataset of human faces Flickr-Faces-HQ with a much higher quality of images and wider variation than in the existing high-resolution datasets.
What does the AI community think?
- Philip Wang, a software engineer at Uber, has created a website thispersondoesnotexist.com where you’ll find the faces generated using StyleGAN. This website went viral.
What are future research areas?
- Exploring the methods for directly shaping the intermediate latent space during training.
What are possible business applications?
- Due to the flexibility of the StyleGAN approach and high quality of it’s resulting images, it is a good candidate for replacing expensive manual media creation in advertising and e-commerce.
Where can you get implementation code?
- The official TensorFlow implementation of StyleGan is available on GitHub, along with pre-trained networks.
Enjoy this article? Sign up for more AI research updates.
We’ll let you know when we release more summary articles like this one.
Leave a Reply
You must be logged in to post a comment.