

High-resolution samples from Stability AI’s 8B rectified flow model
In this article, we delve into ten groundbreaking research papers that expand the frontiers of AI across diverse domains, including large language models, multimodal processing, video generation and editing, and the creation of interactive environments. Produced by leading research labs such as Meta, Google DeepMind, Stability AI, Anthropic, and Microsoft, these studies showcase innovative approaches, including scaling down powerful models for efficient on-device use, extending multimodal reasoning across millions of tokens, and achieving unmatched fidelity in video and audio synthesis.
If you’d like to skip around, here are the research papers we featured:
- Mamba: Linear-Time Sequence Modeling with Selective State Spaces by Albert Gu at Carnegie Mellon University and Tri Dao at Princeton University
- Genie: Generative Interactive Environments by Google DeepMind
- Scaling Rectified Flow Transformers for High-Resolution Image Synthesis by Stability AI
- Accurate Structure Prediction of Biomolecular Interactions with AlphaFold 3 by Google DeepMind
- Phi-3 Technical Report: A Highly Capable Language Model Locally on Your Phone by Microsoft
- Gemini 1.5: Unlocking Multimodal Understanding Across Millions of Tokens of Context by Gemini team at Google
- The Claude 3 Model Family: Opus, Sonnet, Haiku by Anthropic
- The Llama 3 Herd of Models by Meta
- SAM 2: Segment Anything in Images and Videos by Meta
- Movie Gen: A Cast of Media Foundation Models by Meta
If this in-depth educational content is useful for you, subscribe to our AI mailing list to be alerted when we release new material.
Top AI Research Papers 2024
1. Mamba: Linear-Time Sequence Modeling with Selective State Spaces
This paper presents Mamba, a groundbreaking neural architecture for sequence modeling designed to address the computational inefficiencies of Transformers while matching or exceeding their modeling capabilities.
Key Contributions
- Selective Mechanism: Mamba introduces a novel selection mechanism within state space models, tackling a significant limitation of earlier approaches – their inability to efficiently select relevant data in an input-dependent manner. By parameterizing model components based on the input, this mechanism enables the filtering of irrelevant information and the indefinite retention of critical context, excelling in tasks that require content-aware reasoning.
- Hardware-Aware Algorithm: To support the computational demands of the selective mechanism, Mamba leverages a hardware-optimized algorithm that computes recurrently using a scan method instead of convolutions. This approach avoids inefficiencies associated with materializing expanded states, significantly improving performance on modern GPUs. The result is true linear scaling in sequence length and up to 3× faster computation on A100 GPUs compared to prior state space models.
- Simplified Architecture: Mamba simplifies deep sequence modeling by integrating previous state space model designs with Transformer-inspired MLP blocks into a unified, homogeneous architecture. This streamlined design eliminates the need for attention mechanisms and traditional MLP blocks while leveraging selective state spaces, delivering both efficiency and robust performance across diverse data modalities.
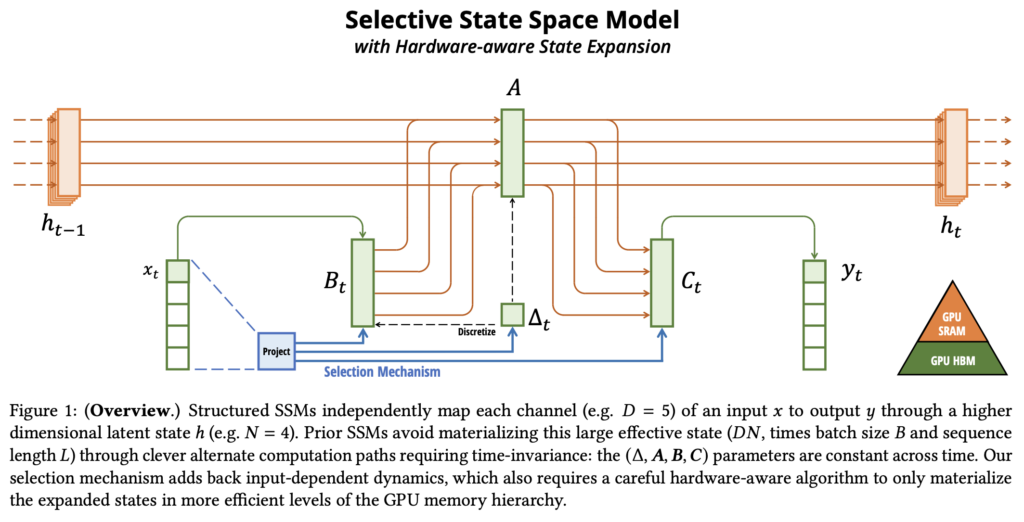
Results
- Synthetics: Mamba excels in synthetic tasks like selective copying and induction heads, showcasing capabilities critical to large language models. It achieves indefinite extrapolation, successfully solving sequences longer than 1 million tokens.
- Audio and Genomics: Mamba outperforms state-of-the-art models such as SaShiMi, Hyena, and Transformers in audio waveform modeling and DNA sequence analysis. It delivers notable improvements in pretraining quality and downstream metrics, including a more than 50% reduction in FID for challenging speech generation tasks. Its performance scales effectively with longer contexts, supporting sequences of up to 1 million tokens.
- Language Modeling: Mamba is the first linear-time sequence model to achieve Transformer-quality performance in both pretraining perplexity and downstream evaluations. It scales effectively to 1 billion parameters, surpassing leading baselines, including advanced Transformer-based architectures like LLaMa. Notably, Mamba-3B matches the performance of Transformers twice its size, offers 5× faster generation throughput, and achieves higher scores on tasks such as common sense reasoning.
2. Genie: Generative Interactive Environments
Genie, developed by Google DeepMind, is a pioneering generative AI model designed to create interactive, action-controllable environments from unannotated video data. Trained on over 200,000 hours of publicly available internet gameplay videos, Genie enables users to generate immersive, playable worlds using text, sketches, or images as prompts. Its architecture integrates a spatiotemporal video tokenizer, an autoregressive dynamics model, and a latent action model to predict frame-by-frame dynamics without requiring explicit action labels. Genie represents a foundation world model with 11B parameters, marking a significant advance in generative AI for open-ended, controllable virtual environments.
Key Contributions
- Latent Action Space: Genie introduces a fully unsupervised latent action mechanism, enabling the generation of frame-controllable environments without ground-truth action labels, expanding possibilities for agent training and imitation.
- Scalable Spatiotemporal Architecture: Leveraging an efficient spatiotemporal transformer, Genie achieves linear scalability in video generation while maintaining high fidelity across extended interactions, outperforming prior video generation methods.
- Generalization Across Modalities: The model supports diverse inputs, such as real-world photos, sketches, or synthetic images, to create interactive environments, showcasing robustness to out-of-distribution prompts.
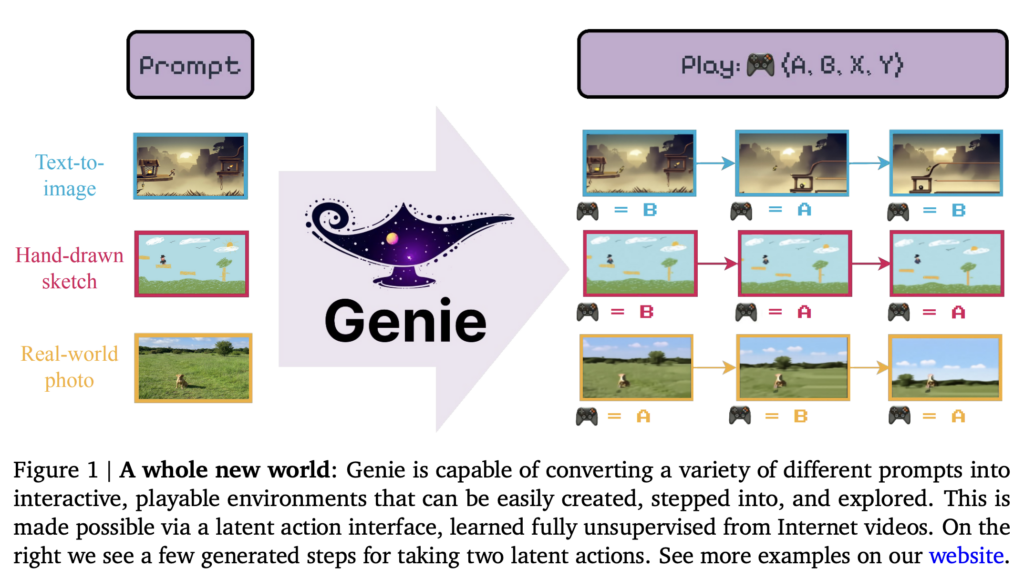
Results
- Interactive World Creation: Genie generates diverse, high-quality environments from unseen prompts, including creating game-like behaviors and understanding physical dynamics.
- Robust Performance: It demonstrates superior performance in video fidelity and controllability metrics compared to state-of-the-art models, achieving consistent latent actions across varied domains, including robotics.
- Agent Training Potential: Genie’s latent action space enables imitation from unseen videos, achieving high performance in reinforcement learning tasks without requiring annotated action data, paving the way for training generalist agents.
3. Scaling Rectified Flow Transformers for High-Resolution Image Synthesis
This paper by Stability AI introduces advancements in rectified flow models and transformer-based architectures to improve high-resolution text-to-image synthesis. The proposed approach combines novel rectified flow training techniques with a multimodal transformer architecture, achieving superior text-to-image generation quality compared to existing state-of-the-art models. The study emphasizes scalability and efficiency, training models with up to 8B parameters that demonstrate state-of-the-art performance in terms of visual fidelity and prompt adherence.
Key Contributions
- Enhanced Rectified Flow Training: Introduces tailored timestep sampling strategies, improving the performance and stability of rectified flow models over traditional diffusion-based methods. This enables faster sampling and better image quality.
- Novel Multimodal Transformer Architecture: Designs a scalable architecture that separates text and image token processing with independent weights, enabling bidirectional information flow for improved text-to-image alignment and prompt understanding.
- Scalability and Resolution Handling: Implements efficient techniques like QK-normalization and resolution-adaptive timestep shifting, allowing the model to scale effectively to higher resolutions and larger datasets without compromising stability or quality.

Results
- State-of-the-Art Performance: The largest model with 8B parameters outperforms open-source and proprietary text-to-image models, including DALLE-3, on benchmarks like GenEval and T2I-CompBench in categories such as visual quality, prompt adherence, and typography generation.
- Improved Sampling Efficiency: Demonstrates that larger models require fewer sampling steps to achieve high-quality outputs, resulting in significant computational savings.
- High-Resolution Image Synthesis: Achieves robust performance at resolutions up to 1024×1024 pixels, excelling in human evaluations across aesthetic and compositional metrics.
4. Accurate Structure Prediction of Biomolecular Interactions with AlphaFold 3
AlphaFold 3 (AF3), developed by Google DeepMind, significantly extends the capabilities of its predecessors by introducing a unified deep-learning framework for high-accuracy structure prediction across diverse biomolecular complexes, including proteins, nucleic acids, small molecules, ions, and modified residues. Leveraging a novel diffusion-based architecture, AF3 advances beyond specialized tools, achieving state-of-the-art accuracy in protein-ligand, protein-nucleic acid, and antibody-antigen interaction predictions. This positions AF3 as a versatile and powerful tool for advancing molecular biology and therapeutic design.
Key Contributions
- Unified Model for Diverse Interactions: AF3 predicts structures of complexes involving proteins, nucleic acids, ligands, ions, and modified residues.
- Diffusion-Based Architecture: In AF3, AlphaFold 2’s evoformer module is replaced with the simpler pairformer module, significantly reducing the reliance on multiple sequence alignments (MSAs). AF3 directly predicts raw atom coordinates using a diffusion-based approach, improving scalability and handling of complex molecular graphs.
- Generative Training Framework: The new approach employs a multiscale diffusion process for learning structures at different levels, from local stereochemistry to global configurations. It mitigates hallucination in disordered regions through cross-distillation with AlphaFold-Multimer predictions.
- Improved Computational Efficiency: The authors suggested an approach to reduce stereochemical complexity and eliminate special handling of bonding patterns, enabling efficient prediction of arbitrary chemical components.
Results
- AF3 demonstrates superior accuracy on protein-ligand complexes (PoseBusters set), outperforming traditional docking tools.
- It achieves higher precision in protein-nucleic acid and RNA structure prediction compared to RoseTTAFold2NA and other state-of-the-art models.
- The model demonstrates a substantial improvement in predicting antibody-protein interfaces, showing a marked enhancement over AlphaFold-Multimer v2.3.
5. Phi-3 Technical Report: A Highly Capable Language Model Locally on Your Phone
With Phi-3, the Microsoft research team introduces a groundbreaking advancement: a powerful language model compact enough to run natively on modern smartphones while maintaining capabilities on par with much larger models like GPT-3.5. This breakthrough is achieved by optimizing the training dataset rather than scaling the model size, resulting in a highly efficient model that balances performance and practicality for deployment.
Key Contributions
- Compact and Efficient Architecture: Phi-3-mini is 3.8B-parameter model trained on 3.3 trillion tokens, capable of running on devices like iPhone 14 entirely offline with over 12 tokens generated per second.
- Innovative Training Methodology: With focus on “data optimal regime,” the team meticulously curated high-quality web and synthetic data to enhance reasoning and language understanding. The model delivers significant improvements in logical reasoning and niche skills due to filtering data for quality over quantity, deviating from traditional scaling laws.
- Long Context: The suggested approach Incorporates the LongRope method to expand context lengths up to 128K tokens, with strong results in long-context benchmarks like RULER and RepoQA.

Results
- Benchmark Performance: Phi-3-mini achieves 69% on MMLU and 8.38 on MT-Bench, rivaling GPT-3.5 while being an order of magnitude smaller. Phi-3-small (7B) and Phi-3-medium (14B) outperform other open-source models, scoring 75% and 78% on MMLU, respectively.
- Real-World Applicability: Phi-3-mini successfully runs high-quality language processing tasks directly on mobile devices, paving the way for accessible, on-device AI.
- Scalability Across Models: Larger variants (Phi-3.5-MoE and Phi-3.5-Vision) extend the capabilities into multimodal and expert-based applications, excelling in language reasoning, multimodal input, and visual comprehension tasks. The models achieve notable multilingual capabilities, particularly in languages like Arabic, Chinese, and Russian.
6. Gemini 1.5: Unlocking Multimodal Understanding Across Millions of Tokens of Context
In this paper, the Google Gemini team introduces Gemini 1.5, a family of multimodal language models that significantly expand the boundaries of long-context understanding and multimodal reasoning. These models, Gemini 1.5 Pro and Gemini 1.5 Flash, achieve unprecedented performance in handling multimodal data, recalling and reasoning over up to 10 million tokens, including text, video, and audio. Building on the Gemini 1.0 series, Gemini 1.5 incorporates innovations in sparse and dense scaling, training efficiency, and serving infrastructure, offering a generational leap in capability.
Key Contributions
- Long-Context Understanding: Gemini 1.5 models support context windows up to 10 million tokens, enabling the processing of entire long documents, hours of video, and days of audio with near-perfect recall (>99% retrieval).
- Multimodal Capability: The models natively integrate text, vision, and audio inputs, allowing seamless reasoning over mixed-modality inputs for tasks such as video QA, audio transcription, and document analysis.
- Efficient Architectures: Gemini 1.5 Pro features a sparse mixture-of-experts (MoE) Transformer architecture, achieving superior performance with reduced training compute and serving latency. Gemini 1.5 Flash is optimized for efficiency and latency, offering high performance in compact and faster-to-serve configurations.
- Innovative Applications: The models excel in novel tasks such as learning new languages and performing translations with minimal in-context data, including endangered languages like Kalamang.

Results
- Benchmark Performance: Gemini 1.5 models surpass Gemini 1.0 and other competitors on reasoning, multilinguality, and multimodal benchmarks. They consistently achieve better scores than GPT-4 Turbo and Claude 3 in real-world and synthetic evaluations, including near-perfect retrieval in “needle-in-a-haystack” tasks up to 10 million tokens.
- Real-World Impact: The evaluations demonstrated that Gemini 1.5 models can reduce task completion time by 26–75% across professional use cases, highlighting its utility in productivity tools.
- Scalability and Generalization: The models maintain performance across scales, with Gemini 1.5 Pro excelling in high-resource environments and Gemini 1.5 Flash delivering strong results in low-latency, resource-constrained settings.
7. The Claude 3 Model Family: Opus, Sonnet, Haiku
Anthropic introduces Claude 3, a groundbreaking family of multimodal models that advance the boundaries of language and vision capabilities, offering state-of-the-art performance across a broad spectrum of tasks. Comprising three models – Claude 3 Opus (most capable), Claude 3 Sonnet (balanced between capability and speed), and Claude 3 Haiku (optimized for efficiency and cost) – the Claude 3 family integrates advanced reasoning, coding, multilingual understanding, and vision analysis into a cohesive framework.
Key Contributions
- Unified Multimodal Processing: The research introduces a seamless integration of text and visual inputs (e.g., images, charts, and videos), expanding the model’s ability to perform complex multimodal reasoning and analysis without requiring task-specific finetuning.
- Long-Context Model Design: Claude 3 Haiku model potentially provides support for context lengths up to 1 million tokens (with the initial production release supporting up to 200K tokens) through optimized memory management and retrieval techniques, enabling detailed cross-document analysis and retrieval at unprecedented scales. The suggested approach combines dense scaling with memory-efficient architectures to ensure high recall and reasoning performance even over extended inputs.
- Constitutional AI Advancements: The research further builds on Anthropic’s Constitutional AI framework by incorporating a broader set of ethical principles, including inclusivity for individuals with disabilities. The alignment strategies are balanced better for helpfulness and safety, reducing refusal rates for benign prompts while maintaining robust safeguards against harmful or misleading content.
- Enhanced Multilingual: The research paper suggests new training paradigms for multilingual tasks, focusing on cross-linguistic consistency and reasoning.
- Enhanced Coding Capabilities: The advanced techniques for programming-related tasks were developed to improve understanding and generation of structured data formats.

Results
- Benchmark Performance: Claude 3 Opus achieves state-of-the-art results in MMLU (88.2% on 5-shot CoT) and GPQA, showcasing exceptional reasoning capabilities. Claude models also set new records in coding benchmarks, including HumanEval and MBPP, significantly surpassing the predecessors and competing models.
- Multimodal Excellence: Claude models also excel in visual reasoning tasks like AI2D science diagram interpretation (88.3%) and document understanding, demonstrating robustness across diverse multimodal inputs.
- Long-Context Recall: Claude 3 Opus achieves near-perfect recall (99.4%) in “Needle in a Haystack” evaluations, demonstrating its ability to handle extensive datasets with precision.
8. The Llama 3 Herd of Models
Meta’s Llama 3 introduces a new family of foundation models designed to support multilingual, multimodal, and long-context processing with significant enhancements in performance and scalability. The flagship model, a 405B-parameter dense Transformer, demonstrates competitive capabilities comparable to state-of-the-art models like GPT-4, while offering improvements in efficiency, safety, and extensibility.
Key Contributions
- Scalable Multilingual and Multimodal Design: Trained on 15 trillion tokens with a multilingual and multimodal focus, Llama 3 supports up to 128K token contexts and integrates image, video, and speech inputs via a compositional approach. The models provide robust multilingual capabilities, with enhanced support for low-resource languages using an expanded token vocabulary.
- Advanced Long-Context Processing: The research team implemented grouped query attention (GQA) and optimized positional embeddings, enabling efficient handling of up to 128K token contexts. Gradual context scaling ensures stability and high recall for long-document analysis and retrieval.
- Simplified Yet Effective Architecture: The models adopt a standard dense Transformer design with targeted optimizations such as grouped query attention and enhanced RoPE embeddings, avoiding the complexity of mixture-of-experts (MoE) models for training stability.
- Enhanced Data Curation and Training Methodology: The researchers employed advanced preprocessing pipelines and quality filtering, leveraging model-based classifiers to ensure high-quality, diverse data inputs.
- Post-Training Optimization for Real-World Use: Post-training strategy Integrates supervised finetuning, direct preference optimization, rejection sampling, and reinforcement from human feedback to improve alignment, instruction-following, and factuality.
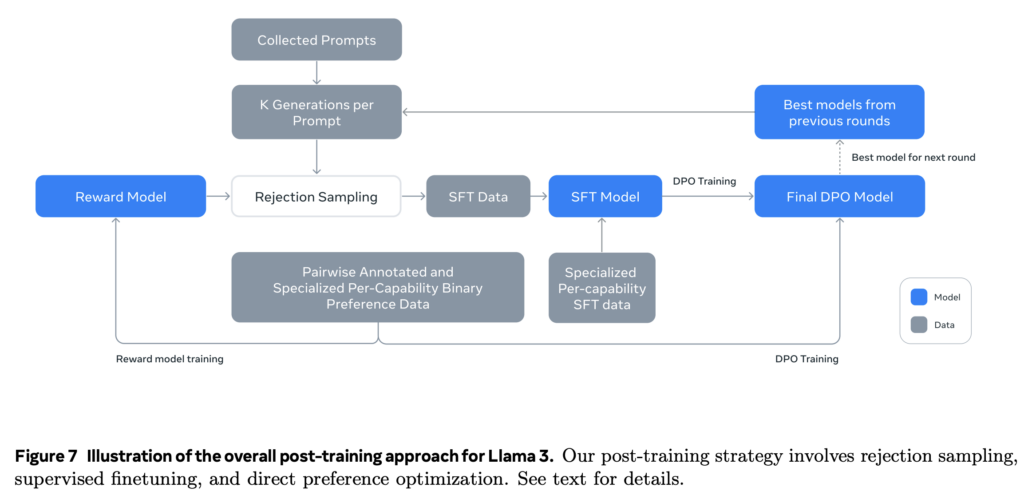
Results
- Benchmark Performance: Llama 3 achieves near state-of-the-art results across benchmarks such as MMLU, HumanEval, and GPQA, with competitive accuracy in both general and specialized tasks. It also excels in multilingual reasoning tasks, surpassing prior models on benchmarks like MGSM and GSM8K.
- Multimodal and Long-Context Achievements: The models demonstrate exceptional multimodal reasoning, including image and speech integration, with preliminary experiments showing competitive results in vision and speech tasks. Also, Llama 3 405B model handles “needle-in-a-haystack” retrieval tasks across 128K token contexts with near-perfect accuracy.
- Real-World Applicability: Llama 3’s multilingual and long-context capabilities make it well-suited for applications in research, legal analysis, and multilingual communication, while its multimodal extensions expand its utility in vision and audio tasks.
9. SAM 2: Segment Anything in Images and Videos
Segment Anything Model 2 (SAM 2) by Meta extends the capabilities of its predecessor, SAM, to the video domain, offering a unified framework for promptable segmentation in both images and videos. With a novel data engine, a streaming memory architecture, and the largest video segmentation dataset to date, SAM 2 redefines the landscape of interactive and automated segmentation for diverse applications.
Key Contributions
- Unified Image and Video Segmentation: SAM 2 introduces Promptable Visual Segmentation (PVS), generalizing SAM’s image segmentation to video by leveraging point, box, or mask prompts across frames. The model predicts “masklets,” spatial-temporal masks that track objects throughout a video.
- Streaming Memory Architecture: Equipped with a memory attention module, SAM 2 stores and references previous frame predictions to maintain object context across frames, improving segmentation accuracy and efficiency. The streaming design processes videos frame-by-frame in real-time, generalizing the SAM architecture to support temporal segmentation tasks.
- Largest Video Segmentation Dataset (SA-V): SAM 2’s data engine enables the creation of the SA-V dataset, with over 35M masks across 50,900 videos, 53× larger than previous datasets. This dataset includes diverse annotations of whole objects and parts, significantly enhancing the model’s robustness and generalization.
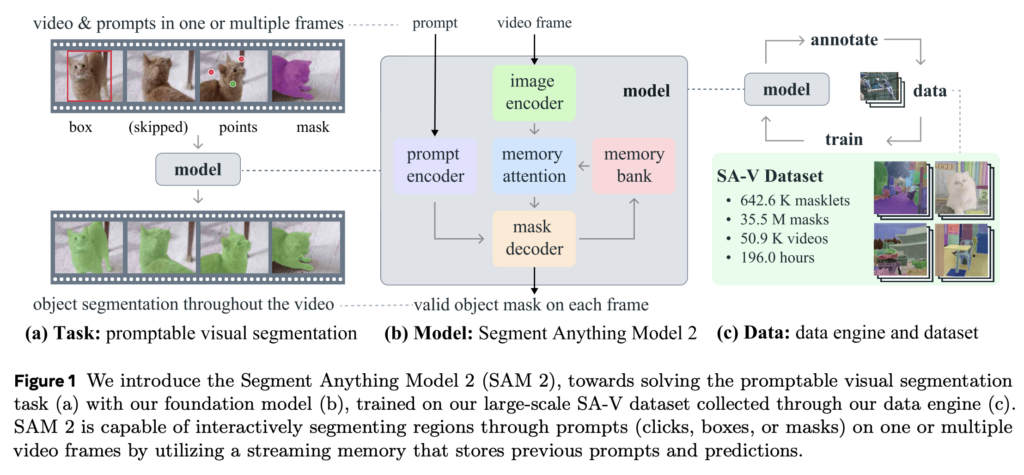
Results
- Performance Improvements: SAM 2 achieves state-of-the-art results in video segmentation, with superior performance on 17 video datasets and 37 image segmentation datasets compared to SAM. It also outperforms baseline models like XMem++ and Cutie in zero-shot video segmentation, requiring fewer interactions and achieving higher accuracy.
- Speed and Scalability: The new model demonstrates 6× faster processing than SAM on image segmentation tasks while maintaining high accuracy.
- Fairness and Robustness: The SA-V dataset includes geographically diverse videos and exhibits minimal performance discrepancies across age and perceived gender groups, improving fairness in predictions.
10. Movie Gen: A Cast of Media Foundation Models
Meta’s Movie Gen introduces a comprehensive suite of foundation models capable of generating high-quality videos with synchronized audio, supporting various tasks such as video editing, personalization, and audio synthesis. The models leverage large-scale training data and innovative architectures, achieving state-of-the-art performance across multiple media generation benchmarks.
Key Contributions
- Unified Media Generation: A 30B parameter Movie Gen Video model trained jointly for text-to-image and text-to-video generation, capable of producing HD videos up to 16 seconds long in various aspect ratios and resolutions. A 13B parameter Movie Gen Audio model that generates synchronized 48kHz cinematic sound effects and music from video or text prompts, blending diegetic and non-diegetic sounds seamlessly.
- Video Personalization: An introduced Personalized Movie Gen Video enables video generation conditioned on a text prompt and an image of a person, maintaining identity consistency while aligning with the prompt.
- Instruction-Guided Video Editing: The authors also introduced Movie Gen Edit model for precise video editing using textual instructions.
- Technical Innovations: The research team developed a temporal autoencoder for spatio-temporal compression, enabling the efficient generation of long and high-resolution videos by reducing computational demands. They implemented Flow Matching as a training objective, providing improved stability and quality in video generation while outperforming traditional diffusion-based methods. Additionally, the researchers introduced a spatial upsampling model designed to efficiently produce 1080p HD videos, further advancing the model’s scalability and performance.
- Large Curated Dataset: The Meta team also presented a curated dataset of over 100 million video-text pairs and 1 billion image-text pairs, along with specialized benchmarks (Movie Gen Video Bench and Movie Gen Audio Bench) for evaluation.
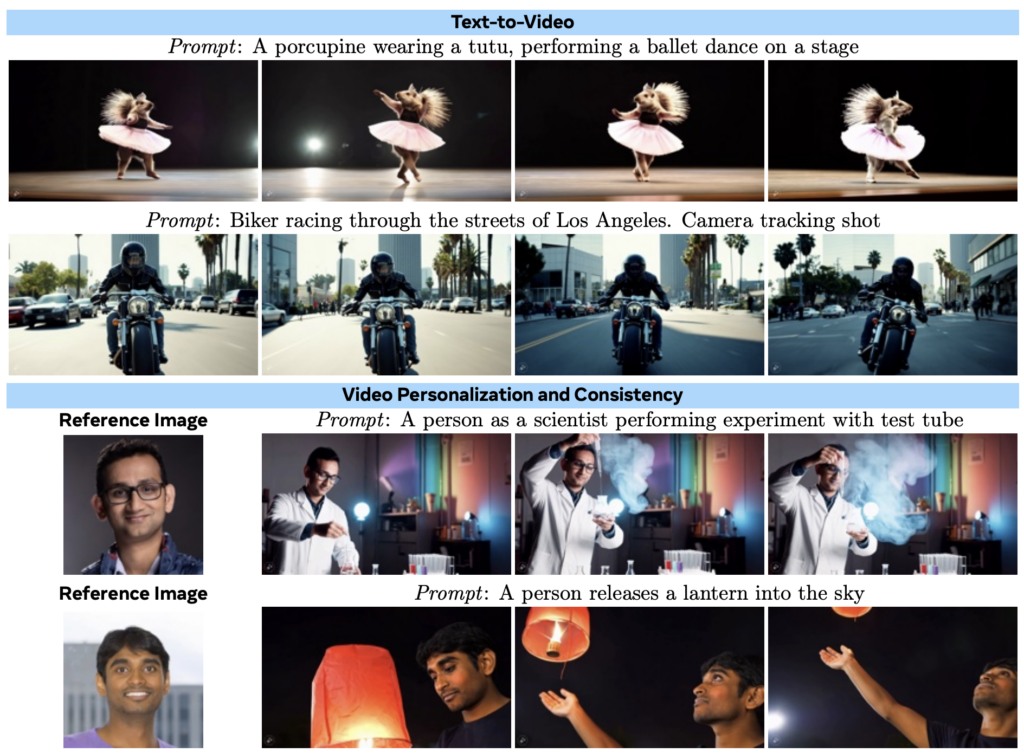
Results
- State-of-the-Art Performance: Movie Gen outperforms leading models like Runway Gen3 and OpenAI Sora in text-to-video and video editing tasks, setting new standards for quality and fidelity. It also achieves superior audio generation performance compared to PikaLabs and ElevenLabs in sound effects and music synthesis.
- Diverse Capabilities: The introduced model generates visually consistent, high-quality videos that capture complex motion, realistic physics, and synchronized audio. It excels in video personalization, creating videos aligned with the user’s reference image and prompt.
Shaping the Future of AI: Concluding Thoughts
The research papers explored in this article highlight the remarkable strides being made in artificial intelligence across diverse fields. From compact on-device language models to cutting-edge multimodal systems and hyper-realistic video generation, these works showcase the innovative solutions that are redefining what AI can achieve. As the boundaries of AI continue to expand, these advancements pave the way for a future of smarter, more versatile, and accessible AI systems, promising transformative possibilities across industries and disciplines.
Enjoy this article? Sign up for more AI research updates.
We’ll let you know when we release more summary articles like this one.