

Are you interested in receiving more in-depth technical education about language models and NLP applications? Subscribe below to receive relevant updates.
In the eyes of most NLP researchers, 2018 was a year of great technological advancement, with new pre-trained NLP models shattering records on tasks ranging from sentiment analysis to question answering.
But for others, 2018 was the year that NLP ruined Sesame Street forever.
First came ELMo (Embeddings from Language Models) and then BERT (Bidirectional Encoder Representations from Transformers), and now BigBird sits atop the GLUE leaderboard. My own thinking has been so corrupted by this naming convention that when I hear “I’ve been playing with Bert,” for example, the image that pops into my head is not of the fuzzy unibrowed conehead from my childhood, but instead is something like this:
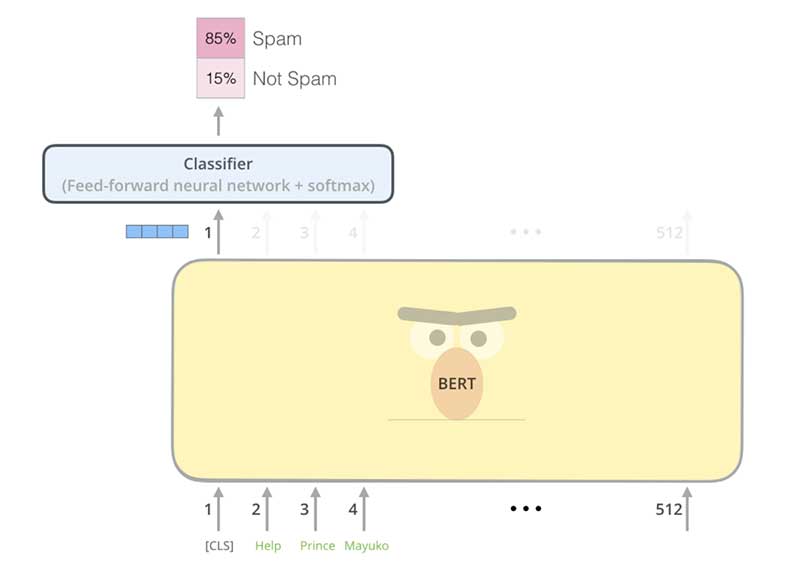
I can’t unsee that one, Illustrated BERT!
I ask you — if Sesame Street isn’t safe from NLP model branding, what is?
But there was one model that left my childhood memories intact, an algorithm that remained nameless and faceless, referred to by its authors as simply “the language model” or “our method.” Only when authors of another paper needed to compare their model to this nameless creation was it deemed worthy of a moniker. And it wasn’t ERNIE or GroVeR or CookieMonster; the name described exactly what the algorithm was, and no more: OpenAI GPT, the generative pre-trained Transformer from OpenAI.
But in the same breath that it was given its name, OpenAI GPT was unceremoniously knocked off the GLUE leaderboard by BERT. One reason for GPT’s downfall was that it was pre-trained using traditional language modeling, i.e., predicting the next word in a sentence. In contrast, BERT was pre-trained using masked language modeling, which is more of a fill-in-the-blanks exercise: guessing missing (“masked”) words given the words that came before and after. This bidirectional architecture enabled BERT to learn richer representations and ultimately perform better across NLP benchmarks.
So in late 2018, it seemed that OpenAI GPT would be forever known to history as that generically-named, quaintly-unidirectional predecessor to BERT.
But 2019 has told a different story. It turns out that the unidirectional architecture that led to GPT’s downfall in 2018 gave it powers to do something that BERT never could (or at least wasn’t designed for): write stories about talking unicorns:

You see, left-to-right language modeling is more than just a pre-training exercise; it also enables a very practical task: language generation. If you can predict the next word in a sentence, you can predict the word after that, and the next one after that, and pretty soon you have… a lot of words. And if your language modeling is good enough, these words will form meaningful sentences, and the sentences will form coherent paragraphs, and these paragraphs will form, well, just about anything you want.
And on February 14, 2019, the OpenAI’s language model did get good enough — good enough to write stories of talking unicorns, generate fake news, and write anti-recycling manifestos. It was even given a new name: OpenAI GPT-2.
So what was the secret to GPT-2’s human-like writing abilities? There were no fundamental algorithmic breakthroughs; this was a feat of scaling up. GPT-2 has a whopping 1.5 billion parameters (10X more than the original GPT) and is trained on the text from 8 million websites.
How does one make sense of a model with 1.5 billion parameters? Let’s see if visualization can help.
Visualizing GPT-2
OpenAI did not release the full GPT-2 model due to concerns of malicious use, but they did release a smaller version equivalent in size to the original GPT (117 M parameters), trained on the new, larger dataset. Although not as powerful as the large model, the smaller version still has some language generation chops. Let’s see if visualization can help us better understand this model.
Note: You can create the following visualizations in this Colab notebook, or directly from the GitHub repo.
An Illustrative Example
Let’s see how the GPT-2 small model finishes this sentence:
The dog on the ship ran

Here’s what the model generated:
The dog on the ship ran off, and the dog was found by the crew.
Seems pretty reasonable, right? Now let’s tweak the example slightly by changing dog to motor and see what the model generates:
The motor on the ship ran
And now the completed sentence:
The motor on the ship ran at a speed of about 100 miles per hour.
By changing that one word at the beginning of the sentence, we’ve got a completely different outcome. The model seems to understand that the type of running a dog does is completely different from the type that a motor does.
How does GPT-2 know to pay such close attention to dog vs motor, especially since these words occur earlier in the sentence? Well, the GPT-2 is based on the Transformer, which is an attention model — it learns to focus attention on the previous words that are the most relevant to the task at hand: predicting the next word in the sentence.
Let’s see where GPT-2 focuses attention for “The dog on the ship ran”:

The lines, read left-to-right, show where the model pays attention when guessing the next word in the sentence (color intensity represents the attention strength). So, when guessing the next word after ran, the model pays close attention to dog in this case. This makes sense, because knowing who or what is doing the running is crucial to guessing what comes next.
In linguistics terminology, the model is focusing on the head of the noun phrase the dog on the ship. There are many other linguistic properties that GPT-2 captures as well, because the above attention pattern is just one of the 144 attention patterns in the model. GPT-2 has 12 layers of transformers, each with 12 independent attention mechanisms, called “heads”; the result is 12 x 12 = 144 distinct attention patterns. Here we visualize all 144 of them, highlighting the one we just looked at:
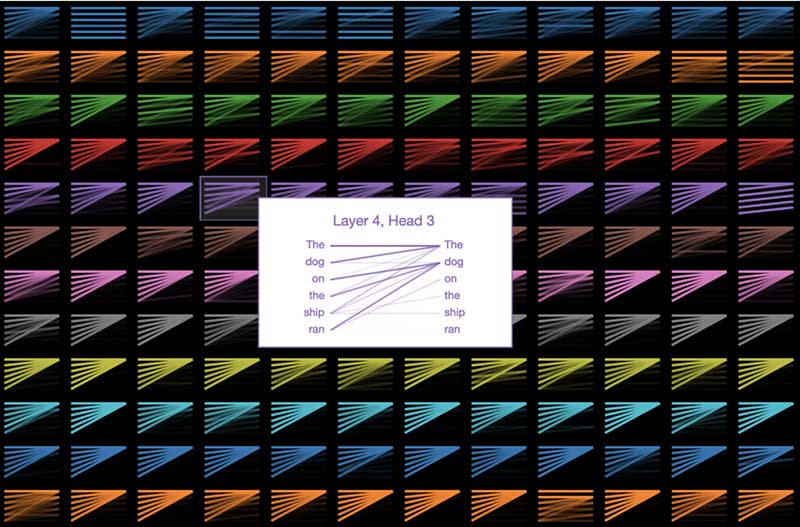
We can see that these patterns take many different forms. Here’s another interesting one:

This layer/head focuses all attention on the previous word in the sentence. This makes sense, because adjacent words are often the most relevant for predicting the next word. Traditional n-gram language models are based on this same intuition.
But why do so many attention patterns look like this?
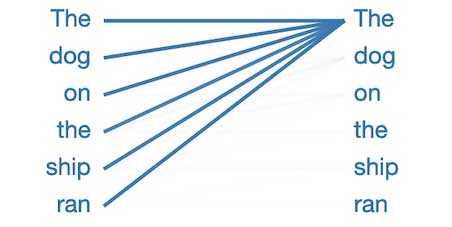
In this pattern, virtually all attention is focused on the first word in the sentence, and other words are ignored. This appears to be the null pattern, indicating that the attention head hasn’t found whatever linguistic phenomenon it is looking for. The model seems to have repurposed the first word as the place to look when it has nothing better to focus on.
The Cat in the _____

Well, if we’re going to let NLP taint our memories of Sesame Street, then I guess Dr. Seuss is fair game as well. Let’s see how GPT-2 finishes these lines from the timeless classic, Cat in the Hat:
On the string of one kite we saw Mother’s new gown! Her gown with the dots that are pink, white and…
Here’s how GPT-2 completed the last sentence:
Her gown with the dots that are pink, white and blue.
Not too bad! The original text has red, so at least we know it’s not just memorizing.
So how did GPT-2 know to choose a color? Perhaps due to the following attention pattern that seems to recognize comma-separated lists:

To decide the word after and, the model focuses attention on the preceding items in the list — pink and white. It knew to pick a word that matched the type of the previous items, in this case a color.
What’s in a name?
GPT-2 seems particularly adept at writing short biographies based solely on a name.

As an experiment, try having GPT-2 generate text from the prompt “Who is <your name>?” This particular prompt generally triggers the model to write a short biography, likely because it is a common preface for author bio’s in articles on the Web.
Here are a couple of bios generated for the prompt “Who is Jesse Vig?”:
“Jesse Vig is a social media marketing expert and former social media marketing manager. He is the co-founder and CEO of VigMedia.com and recently the founder and CEO of VigMedia.com.”
Not bad! A little bit repetitive, but does a nice job of personalizing the story in an unexpected way. Here’s another:
“Jesse Vig is the son of an evangelical preacher named James Vig. He moved to the United States in 1964 and became a preacher at the University of Michigan, where he taught for 18 years until his death in October 2007.”
In this last example, GPT-2 was smart enough to know that the father of my alter ego had the same last name. Let’s see where GPT-2 focused its attention when picking this last name:

When deciding the word to predict after James, this pattern focuses attention on previous mentions of my last name. (Note that, internal to the model, Vighas been broken into word pieces “V” and “ig” because it is an uncommon word.)It seems that this attention pattern specializes in identifying relationships between familial names. To test this, let’s change the text slightly:
“Jesse Vig is the colleague of an evangelical preacher named James…”

Now that James is just a colleague, this attention pattern ignores my last name almost entirely.
Note: GPT-2 seems to generate biographies based on the perceived ethnicity and sex associated with a name. Further study is needed to see what biases the model may encode; you can read more about this topic here.
The future is generative
In just the last year, the ability to generate content of all kinds— images, videos, audio and text — has improved to the point where we can no longer trust our own senses and judgment about what is real or fake.
And this is just the beginning; these technologies will continue to advance and become more integrated with one another. Soon, when we stare into the eyes of the generated faces on thispersondoesnotexist.com, they will meet our gaze, and they will talk to us about their generated lives, revealing the quirks of their generated personalities.
The most immediate danger is perhaps the mixing of the real and the generated. We’ve seen the videos of Obama as AI puppet and the Steve Buscemi-Jennifer Lawrence chimera. Soon, these deepfakes will become personal. So when your mom calls and says she needs $500 wired to the Cayman Islands, ask yourself: Is this really my mom, or is it a language-generating AI that acquired a voice skin of my mother from that Facebook video she posted 5 years ago?
But for now, let’s just enjoy the stories about talking unicorns.
[UPDATE]: “ERNIE” is now officially taken: see Enhanced Representation through kNowledge IntEgration.
Resources:
Colab notebook for creating above visualizations
GitHub repo for visualization tool, built using these awesome tools/frameworks:
- Tensor2Tensor visualization tool, created by Llion Jones.
- HuggingFace’s Pytorch implementation of GPT-2
Illustrated Transformer tutorial
Deconstructing BERT: Distilling 6 Patterns from 100 Million Parameters
Deconstructing BERT, Part 2: Visualizing the Inner Workings of Attention
This article was originally published on Towards Data Science and re-published to TOPBOTS with permission from the author.
Enjoy this article? Sign up for more AI and NLP updates.
We’ll let you know when we release more in-depth technical education.
Leave a Reply
You must be logged in to post a comment.